Zonos TTS - Advanced AI Text-to-Speech with Voice Cloning Technology
Zonos TTS is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers. Experience the power of Zonos AI voice cloning technology.
Key Features
- •Zonos AI zero-shot voice cloning technology
- •Multilingual TTS support (EN, JP, CN, FR, DE)
- •Advanced audio quality and emotion control
- •Real-time Zonos TTS generation (2x speed on RTX 4090)
🎁 Experience the future of text-to-speech technology
Voice Playground
Experience the power of Zonos TTS text-to-speech directly in your browser. Try out different voices, test voice cloning, and generate high-quality speech instantly.
What is Zonos TTS
Zonos TTS v0.1 is a leading open-weight text-to-speech model trained on more than 200k hours of varied multilingual speech, delivering expressiveness and quality on par with—or even surpassing—top TTS providers. Discover the power of Zonos AI voice cloning technology.
- Zonos TTS Zero-shot Voice CloningInput desired text and a 10-30s speaker sample to generate high quality Zonos TTS output with accurate voice cloning capabilities.
- Zonos TTS Audio Prefix InputsAdd text plus an audio prefix for even richer speaker matching and behaviors like whispering that are challenging to replicate with Zonos AI.
- Zonos TTS Fine-grained ControlControl speaking rate, pitch variation, audio quality, and emotions such as happiness, fear, sadness, and anger with Zonos AI.
Why Choose Zonos TTS
Get everything you need for high-quality Zonos AI text-to-speech generation with advanced voice cloning and emotion control.
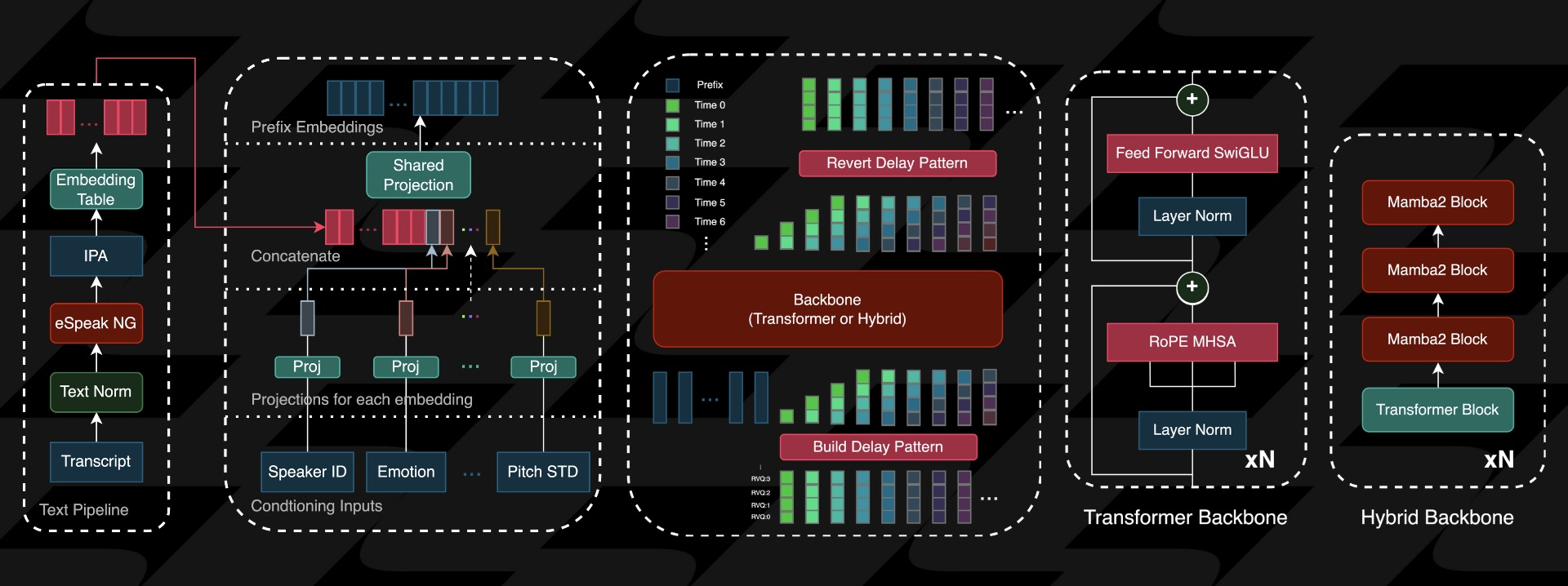
What makes Zonos TTS special
Zonos TTS is a leading open-weight text-to-speech model that combines high quality, flexibility, and ease of use for voice cloning applications.
Zonos TTS zero-shot voice cloning
Input desired text and a 10-30s speaker sample to generate high quality Zonos TTS output
Zonos TTS audio prefix inputs
Add text plus an audio prefix for even richer speaker matching with Zonos AI. Audio prefixes can be used to elicit behaviours such as whispering
Zonos TTS multilingual support
Zonos TTS v0.1 supports English, Japanese, Chinese, French, and German
Zonos TTS audio quality and emotion control
Fine-grained control of many aspects including speaking rate, pitch, maximum frequency, audio quality, and various emotions with Zonos AI
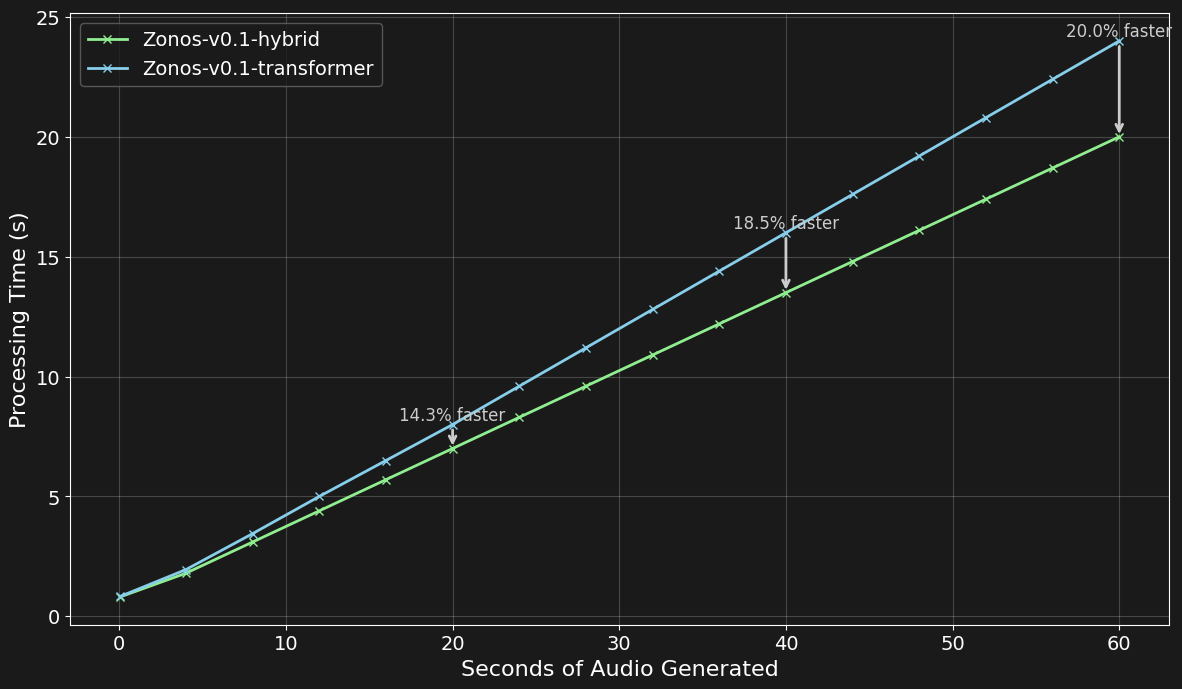
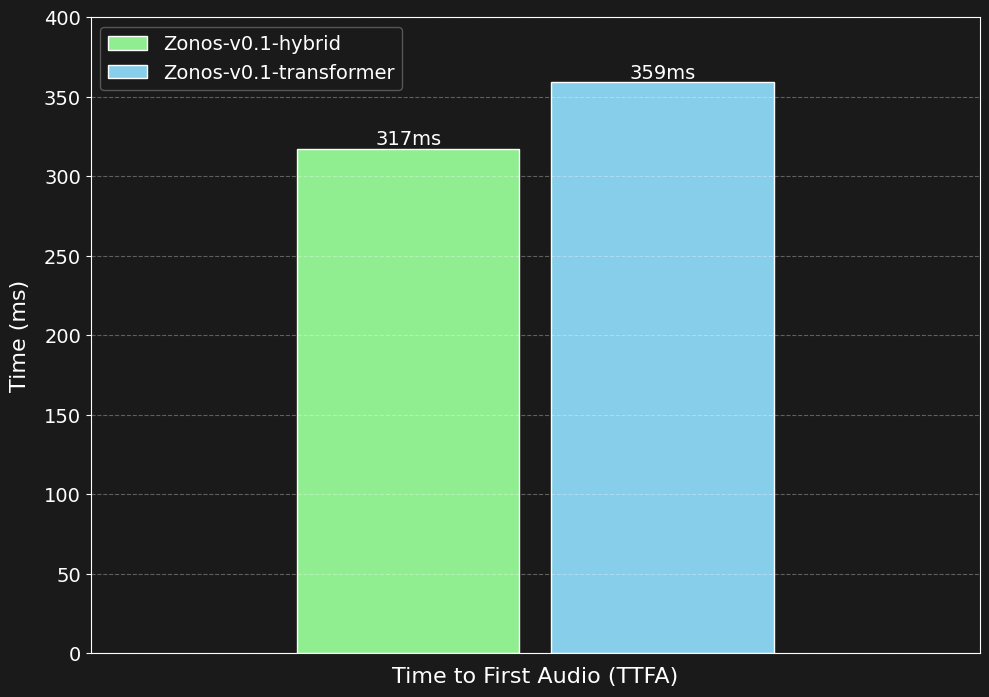
Zonos TTS fast generation
Zonos TTS runs with a real-time factor of ~2x on an RTX 4090 (generates 2 seconds of audio per 1 second of compute time)
Zonos TTS simple installation and deployment
Zonos TTS comes packaged with an easy to use gradio interface and can be installed and deployed simply using docker
What People Are Saying About Zonos TTS
See what the community thinks about Zonos TTS voice cloning technology.
Wow that's very impressive
— Paul Couvert (@itsPaulAi) February 10, 2025
Zonos is a 100% open source AI model that can clone any voice 🤯
You can basically run it anywhere as it's only 1.6B parameters.
Link belowpic.twitter.com/yztyL46NvN
自分の声質でテキストから音声を瞬時に複製できる「Zonos-v0.1」が公開。話す速度や喜怒哀楽を含めた感情も調整可能。つまり音声クローンを創り上げることが出来る。オーディオファイルで学習するので、結論自分の声質以外も学習可能なので、悪用厳禁。詳細はリプ欄へ。 pic.twitter.com/VixYXJXrAG
— みるぼん@スモビジ (@milbon_) February 11, 2025
新发布的最强开源语音模型 Zonos
— 歸藏(guizang.ai) (@op7418) February 11, 2025
语音生成质量非常高,而且这次有中文
- 两种1.6B 模型,transformer 和 SSM
- 用5到30秒的语音进行高保真语音克隆
- 可以调节速度,音高,音频质量和情绪
- 添加文本和音频前缀,实现更丰富的说话人匹配效果
-在 RTX 4090 显卡上运行时,实时率约为 2 倍 pic.twitter.com/hF6qa9JqKW
This is not being talked about enough
— AP (@angrypenguinPNG) February 14, 2025
Zonos is a new open-source voice AI model that clones any voice in under 10 seconds.
Here is how I made a voice clone of @mreflow ! pic.twitter.com/SDEkAH1HOJ
Run ZONOS Locally
— cocktail peanut (@cocktailpeanut) February 15, 2025
ZONOS, the new SOTA Open Source Voice Cloning TTS, is here.
I've managed to write a 1-click launcher for Zonos that works on Mac, Windows, and Linux (ALL platforms!)
Here's me cloning Peter Griffin's voice on my Mac. https://t.co/XLB6NEU8gE pic.twitter.com/nQcVtXE4P
What the heck, this is an AI-generated voice and open source too under Apache 2.0 license. Damn! 🔥🔥
— AshutoshShrivastava (@ai_for_success) February 10, 2025
Zonos Beta is a new open-source highly expressive TTS model with high-fidelity voice cloning from @ZyphraAI
Try it here 👇pic.twitter.com/GGn877CzGp
Frequently Asked Questions About Zonos TTS
Have another question about Zonos TTS? Contact us by email.
What are the Zonos AI system requirements?
Zonos TTS requires Linux (preferably Ubuntu 22.04/24.04) or macOS, and a GPU with 6GB+ VRAM. The Hybrid model additionally requires a 3000-series or newer Nvidia GPU. Zonos TTS can also run on CPU but will be significantly slower.
Can I run Zonos TTS on Windows?
For experimental Windows support, check out the Windows fork of Zonos. However, Linux or macOS is recommended for the best Zonos TTS experience.
How do I get started with Zonos TTS?
You can try Zonos TTS directly in your browser using our online demo, or install it locally using pip or docker. Check out our documentation for detailed Zonos AI installation and usage instructions.
What languages does Zonos TTS support?
Zonos TTS currently supports English, Japanese, Chinese, French, and German. We are continuously working to add support for more languages in Zonos TTS.
How does Zonos TTS voice cloning work?
Zonos TTS can clone a voice from just a few seconds of audio (10-30s recommended). Simply provide a reference audio clip along with your text, and Zonos AI will generate speech in that voice.
Can I use Zonos TTS for commercial purposes?
Yes, Zonos TTS can be used for commercial purposes under our licensing terms. Please refer to our Terms of Service for specific usage guidelines.
Ready to try Zonos TTS?
Experience the power of Zonos AI open-source text-to-speech with voice cloning.